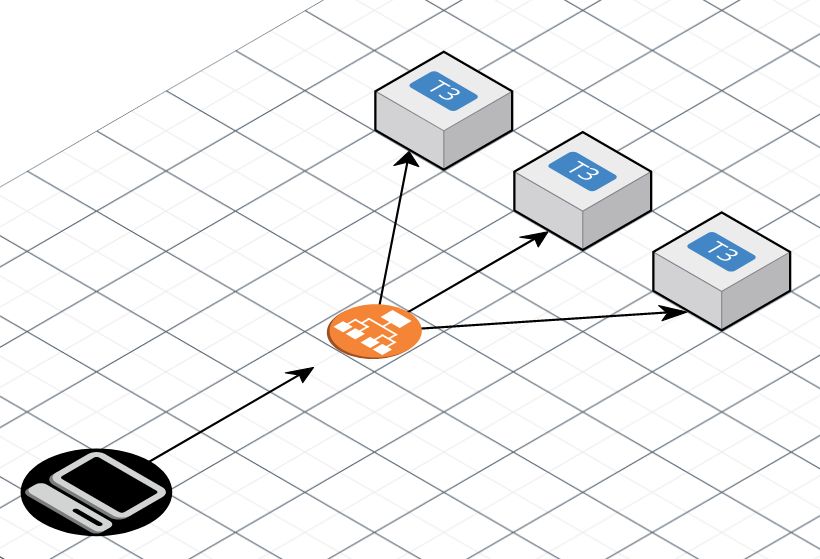
Descripción
La arquitectura es la que se muestra en la imagen de arriba.
La aplicación estaba formada por varias instancias t3 de AWS hacen uso de Nginx para servir una aplicación PHP gestionado por PHP-FPM. Los clientes, están representados como el ordenador negro, y hacen llamadas REST al Application Load Balancer, y es este componente el que enrutará las peticiones hacia las instancias t3 que están situadas dentro de el Target Group.
La instancia entonces recibirá la petición, la procesará y finalmente retornará el resultado. El problema de que empiecen a colapsar todas las peticiones no se pudo resolver ni añadiendo instancias al backend ni incrementando el tamaño de las mismas, y el problema se iba repitiendo aleatoriamente a lo largo del tiempo. Además las instancias del Target Group que estaban sobrecargadas seguían reportándose como healthy así que el ALB no paraba de enrutar peticiones hacia ellas. El intento de analizar individualmente el código que se ejecutaba para cada una de las peticiones tampoco fue de ayuda porque al final aparecían todo tipo de peticiones a todo tipo de endpoints y no se observaba un patrón. La única correlación aparente es que el problema se producía muchas veces al recibir ráfagas de tráfico intensas desde los clientes pero esto no siempre ocurría.
Análisis de la situación
El primer paso para analizar una situación de emergencia es una buena adquisición de información. Tendremos que obtener todas las fuentes de información posibles sobre el sistema, los componentes y lo que pueda estar involucrado, trataremos de buscar datos, y documentación acerca de los componentes. Empezamos con el síntoma más aparente que son los timeouts.
Para entender porqué puede ocurrir un timeout hay que saber primero cómo se pasan las requests de un componente a otro. En este caso particular el primer componente en recibir la request es el ALB. Los balanceadores de AWS vienen con un parámetro de configuración llamado idle timeout. El Load Balancer pasa la request al siguiente componente y espera una respuesta, este es el tiempo máximo que esperar a los componentes que hay debajo para que den una respuesta, si pasa este tiempo y no se ha recibido respuesta informará directamente al cliente indicando que la respuesta he excedido el tiempo máximo.
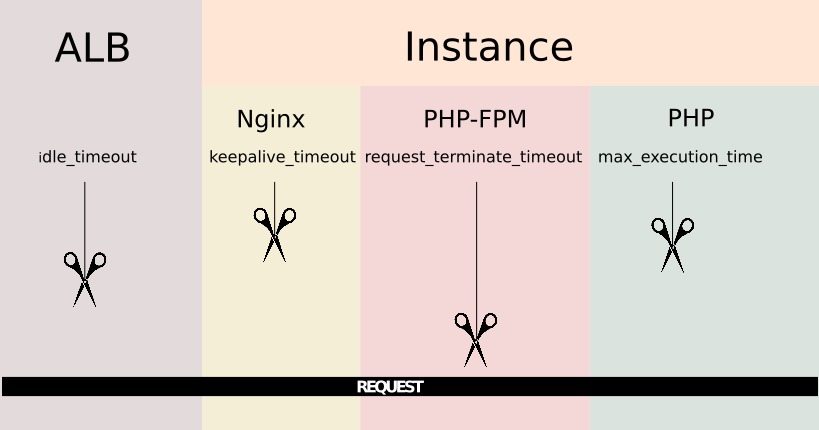
Si continuamos al siguiente componente llegaremos la instancia, Como mencionamos, la instancia ejecuta Nginx así que será este programa el que se ocupará de la request a partir de ahora. Tiene una directiva de configuración llamada keepalive_timeout por la que Nginx cerrará las conexiones con el cliente cuando expire este periodo de tiempo.
Siguiendo hacia abajo, Nginx pasa la petición a PHP-FPM utilizando las directivas fastcgi. Ahora será PHP-FPM el que tienen la petición y puede también tirar la petición por exceso de tiempo basándose en el valor de la directiva request_terminate_timeout de la configuración del pool i. e. /etc/php/7.2/fpm/pool.d/www.conf, esta opción viene deshabilitada por defecto. Finalmente PHP además trae su propia configuración de timeout llamada max_execution_time situada en etc/php/7.2/fpm/php.ini. La cadena de posibles timeouts queda del siguiente modo, se puede imaginar como un conjunto de tijeras bajando a distintas distancias sobre un hilo que van a cortar, que es la request, la primera que llegue cortará la comunicación.
Una vez que se tiene esta imagen en mente hice una prueba de concepto con un escenario similar que contuviera un script de PHP simple que provocará timeouts realizando cálculos matemáticos, no con sleep porque para determinados timeouts bajo sistemas unix los sleep no cuentan dentro del tiempo de timeout.). Jugando con los valores de configuración explicados se puede ir cortando la conexión desde distintos componentes y observando los resultados.
Algunas observaciones valiosas fueron:
Timing out de una respuesta debido al max_execution_time de PHP dejará el siguiente mensaje ne el error log de nginx i.e. /var/log/nginx/error.log pero nada en el log de PHP-FPM:
En caso de finalizar la conexión porque la directiva request_terminate_timeout de PHP-FPM es la que lo provoca, dejará el siguiente mensaje en el error log de Nginx:
Pero además este mensaje aparecerá en el log de PHP-FPM ii.e. /var/log/php-fpm7.2.log:
Si es Nginx el que corta la conexión dejará este mensaje en su error log:
Y finalmente si es el ALB el que corta la conexión no aparecerán mensajes en los logs de la instancia porque puede que incluso siga procesando la petición cuando el balanceador informe al cliente de que la petición ha superado el tiempo máximo.
Peticiones lentas
Una vez que se ha entendido y testeado toda la configuración de timeouts, es tiempo de identificar qué hace que las peticiones empiecen a colapsar y a requerir cada vez más tiempo para ser procesadas hasta que se empiezan a alcanzar los valores máximos y producirse los timeouts. Cuando testeaba los timeouts pude observar estos mensajes en los logs de PHP-FPM:
Como esto apunta a la configuración del gestor procesos de PHP-FPM el siguiente paso será forzar situaciones de saturación de recursos. Para configurar el gestor de procesos manipulé las directivas pm, max_children, start_servers, min_spare_servers, max_spare_servers y process_idle_timeout. Probé diferentes configuraciones e hice algunos tests de estrés donde pude replicar exactamente lo que estaba pasando en el servidor de producción.. Cuando se tiene la directiva pm de PHP-FPM's ajustada al valor dynamic mientras que max_children y spare_servers están steados a 1 Pude realizar peticiones concurrentes que tardarían varios segundos en ser procesadas. En un escenario de escasez de recursos de PHP las peticiones se empiezan a encolar y su tiempo de procesamiento empieza a crecer exponencialmente hasta alcanzar los valores de timeout. Aquí hay una comparativa del comportamiento de unas pocas peticiones en ambos escenarios.
La razón de esto es que PHP-FPM reserva tiene algunos “huecos” definidos para tratar peticiones entrantes, una vez que una petición ocupa uno de estos huevos la siguiente petición irá al siguiente “hueco” disponible. Si todos los huecos están ocupados el mensaje del que hablamos antes aparecerá en el log de PHP-FPM y la petición esperará a que alguno de los procesos que ya están ocupados se libere. Todo este tiempo de espera contará para que la petición se pueda descartar por timeout así que si están llegando peticiones a un ritmo superior al que se están procesando se empezarán a encolar indefinidamente y esta es la causa exacta que hacía que se nos cayeran los sistemas.
La primera medida a tomar para evitar esto es ajustad la configuración del gestor de procesos de PHP-FPM en las instancias de EC2 de producción. Hay muchas maneras de hacer esto, y estuve leyendo bastantes articulos al respecto. Finalmente me decanté por una configuración estática del gestor de procesos ajustada a la memoria RAM disponible en las instancias y al tamaño medio de memoria de un proceso PHP en el sistema. También añadí unas gráficas y alertas de memoria libre de las instancias en Amazon Cloudwatch para poder controlar gráficamente el consumo de memoria y ver cuánta quedaba libre.
También decidí activar el parámetro max_requests para evitar fugas de memoria, este parámetro hará que PHP-FPM reinicie después de un número de peticiones gestionadas así que es conveniente para evitar una posible degradación del proceso.
Después de ajustar los timeouts y la gestión de procesos de PHP-FPM la aplicación empezó a gestionar de manera adecuada las rachas de peticiones enviadas por el cliente, y se podía haber parado ahí, pero queda una cosa más. Cuando PHP-FPM empezaba a sobrecargarse en una instancia el balanceador de carga no paraba de enviarle peticiones nuevas, esto es debido a que el balanceador de carga no tenía conocimiento del estado de PHP-FPM porque el healthcheck del target group estaba siendo resuelto directamente por Nginx. Si nos acordamos de la cadena de elementos que tratan la petición de antes, era Nginx el que recibía y resolvía la petición de healthcheck y no la pasaría hacia abajo, esto funcionaba y era correcto, respondería con OK y la máquina aparecería saludable gracias a este bloque de servidor:
server {
listen 80 default_server;
location /health-status {
access_log off;
return 200;
}
}
Pero si estamos sufriendo situaciones como la de este documento no se reportarán. Se puede usar a nuestro favor el hecho de que PHP-FPM ya viene con un reporte de estado y un servicio de ping que vienen deshabilitados por defecto, pero que pueden ser fácilmente habilitados ajustando los parámetros pm.status_path y ping.path, en la configuración del pool. Así que el nuevo bloque de servidor para nuestra instancia será:
server {
listen 80 default_server;
location ~ ^/(ping)$ {
acess_log off;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; fastcgi_index index.php;
include fastcgi_params;
fastcgi_pass unix:/var/run/php/php7.2-fpm.sock;
}
}
Habilitando la página de estado de PHP-FPM se obtiene información valiosa sobre la gestión de procesos que está haciendo, dejo para un futuro el posible volcado de esta información a métricas de Amazon Cloudwatch porque podría ser bastante interesante e útil.
Todo el conjunto de medidas resultante de la investigación se implementaron en las máquinas de producción y se estuvieron monitorizando durante algunos días.Después de comprobar que se procesaban adecuadamente las ráfagas de tráfico del client sin llegar a tiempos de timeout quedaba un paso final todas las máquinas se configuran automáticamente en función de las recetas de Chef que tenemos. Hay que incluir estas medidas en las recetas para que cada máquina que se levante quede automáticamente bien configurada. Para descomentar líneas y ajustar valores en los ficheros de configuración he hecho uso de bloques de ruby como:
ruby_block 'replace_line' do
block do
file = Chef::Util::FileEdit.new('/etc/php/7.2/fpm/pool.d/www.conf')
file.search_file_replace_line(';pm.status_path = /status', 'pm.status_path = /status')
file.search_file_replace_line(';ping.path = /ping', 'ping.path = /ping')
file.write_file
end
end
And then check the results on the kitchen tests like:
describe file('/etc/php/7.2/fpm/pool.d/www.conf') do
its('content') { should match(%r{^pm.status_path = /status}) }
its('content') { should match(%r{ping.path = /ping}) }
end
Así he podido setear todos los parámetros estáticos de la configuración a excepción de pm.max_children porque como vimos antes, este parámetro no se puede calcular de manera segura sin conocer datos sobre el consumo real de memoria de la aplicación en la máquina, pero se puede hacer una aproximación basándose en el tamaño de la RAM. He asumido que la cantidad promedio de memoria consumida por un proceso es de 50 MB que puede que no siempre sea el valor real pero prefiero ser conservador, También he reservado 300 MB libres por si acaso:
# Max childrencalculation
memory_in_megabytes =
case node['os']
when /.*bsd/
node['memory']['total'].to_i / 1024 / 1024
when 'linux'
node['memory']['total'][/\d*/].to_i / 1024
when 'darwin'
node['memory']['total'][/\d*/].to_i
when 'windows', 'solaris', 'hpux', 'aix'
node['memory']['total'][/\d*/].to_i / 1024
end
average_process_need = 50
unused_memory = 300
max_children = (memory_in_megabytes - unused_memory) / average_process_need
ruby_block 'set_max_children' do
block do
file = Chef::Util::FileEdit.new('/etc/php/7.2/fpm/pool.d/www.conf')
file.search_file_replace_line('pm.max_children = 5', "pm.max_children = #{max_children}")
file.write_file
end
End
Ahora como se ha definido en el .kitchen.yml que los tests correrán en máquinas t2.micro de EC2 puedo saber de antemano el número de max_children that que resultan de hacer el cálculo al ejecutar los tests de kitchen:
its('content') { should match(/^pm.max_children = 13/) }Vale la pena mencionar además que el servicio php7.2-fpm se tiene que reiniciar para que se apliquen los cambios en la configuración. Ahora, después de comprobar que el estado de las máquinas es el correcto podemos crear y destruir de manera segura máquinas y redirigir el tráfico del cliente a las mismas sin cortes.